
製品情報
オンラインヘルプ
1. 使用条件
2. セットアップ方法
3. 操作方法
3.1 テキストスキャン
3.2 言語モデル
3.3 グリッド形式
1. 使用条件
- インターネット接続が必要となります。
- 同一事業所内に限り、読取回数、使用期間の範囲で、台数に制限なく複数のコンピューターにインストールできます。
- テキストスキャン対象の画像はクラウド上のAI-OCRサービスにアップロードし、テキストデータ解析を行います。クラウド上のAI-OCRサービスとの通信(アップロードおよび解析結果の入手)は暗号化しております。また、クラウド上にデータを保存しておらず、送信した画像が第三者と共有または公開されることはありませんが、機密性の高い文書を読み取りなど懸念が生じる可能性がある場合は、ご利用を控えて頂くようお願いします。
2. セットアップ方法
セットアップウィザードに沿ってインストールします。
インストール後、「もじコピ!」を右クリックメニューの「管理者として実行」で起動し、ライセンス画面でシリアル番号を入力してライセンス認証してください。(ライセンス認証後は、通常の起動方法で利用可能です。)
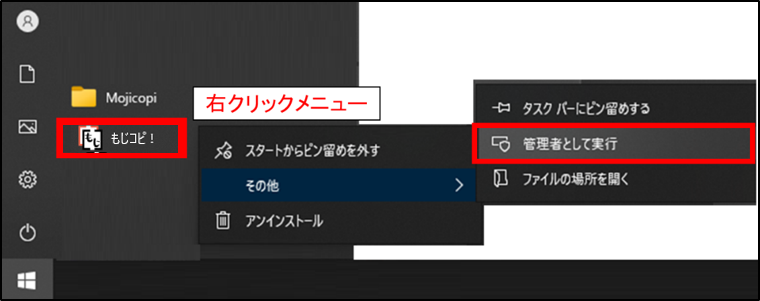
[ライセンス]をクリックします。
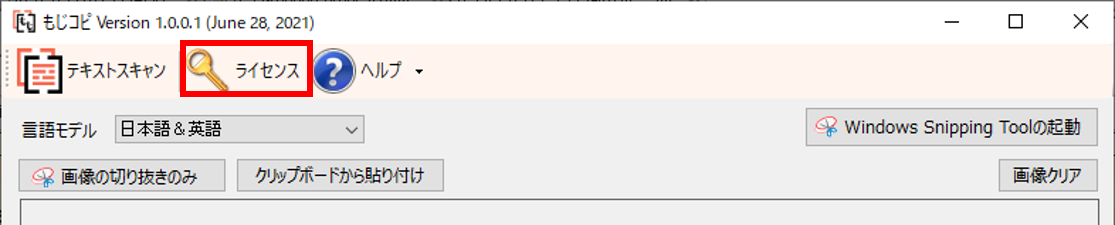
[シリアル番号]を入力し、[認証]を行います。
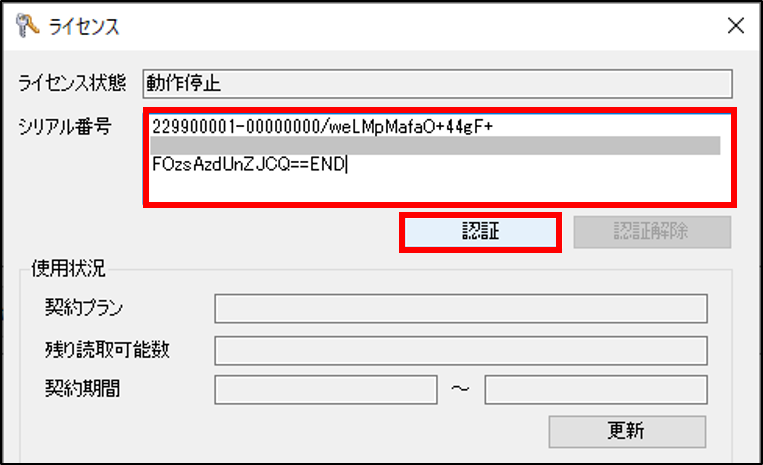
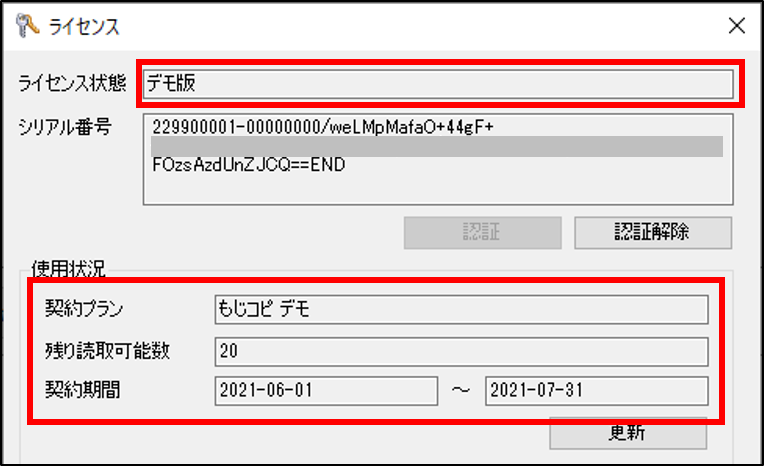
[ライセンス状態]と[使用状況]が適切に表示されれば認証完了です。
3. 操作方法
3.1 テキストスキャン
読み取りたいPDFファイルや画像ファイル、WEBサイトなどを開きます。
[テキストスキャン]を押すと、背面にあるスクリーン全体が灰色で表示されるので、マウスの左クリックした状態でドラッグ操作を行い、範囲選択します。
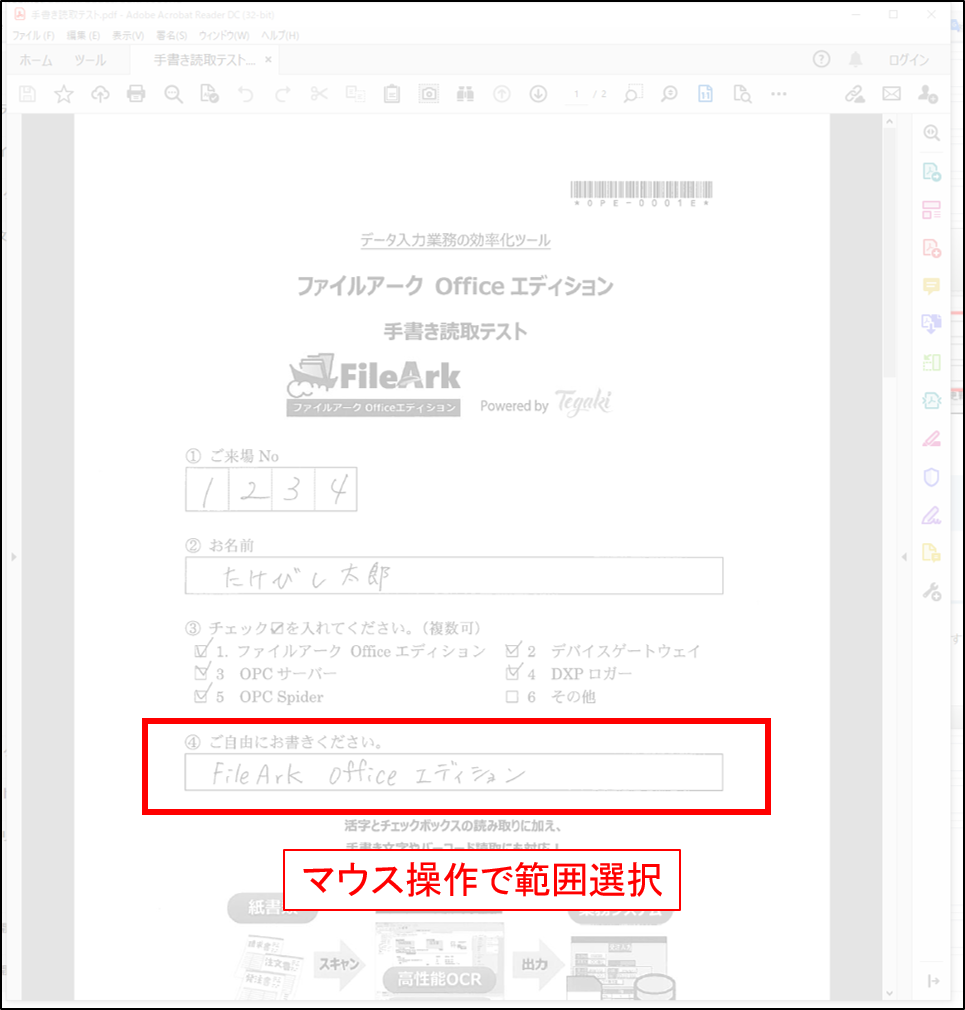
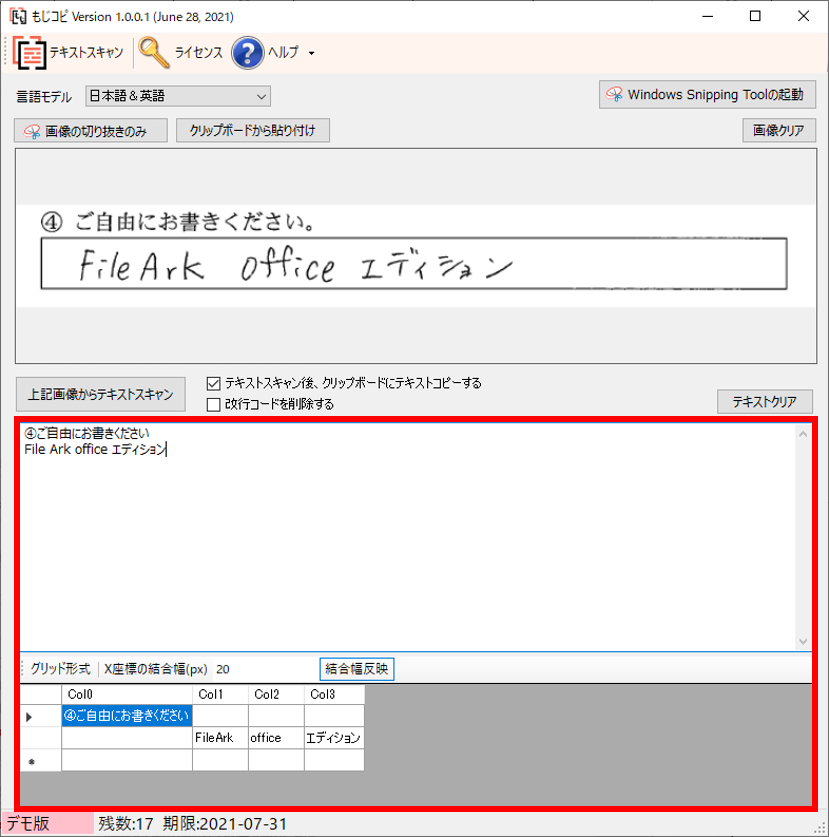
範囲選択が完了すると、テキスト抽出されます。そのままテキストデータがクリップボードにコピーされます。グリッド形式のデータをエクセルに貼り付けて活用することもできます。
3.2 言語モデル
読取時の言語モデルを指定できます。言語モデルの種類は以下の通りです。
※この表は横にスクロールできます
| 言語モデル | 内容 |
|---|---|
| 日本語&英語 | 日本語もしくは英語として読み取ります。 |
| 日本語 | 日本語として読み取ります。 |
| 英語 | 英語として読み取ります。 |
| 指定なし (言語自動判定) |
言語を自動判定して読み取ります。日本語、英語以外を読み取る場合はこちらを指定してください。 |
3.3 グリッド形式
読み取った文字データの座標(X,Y座標)データを活用して、グリッド形式で各セルに表示します。表などの読み取りに利用します。範囲選択して[Ctrl+C]でコピーしてエクセルなどに貼り付け可能です。
読み取り結果がセル毎に自動分割されますが、期待する区切りで分割されない場合があります。そうした場合は、[X座標の結合幅(px)]を指定し、[結合幅反映]で調整できます。結合されるセルはX座標が結合幅に収まるセルのみです。Y座標には適用されません。